AI推論 最適化技術 Cache AI®
LLM時代のAI実運用を支える推論最適化技術
Geek Guildは、AI推論の効率化・最適化に関する研究開発を基盤に、企業のLLM活用を支援します。中核技術であるCache AIにより、社内LLM、問い合わせ対応AI、AIエージェントなど、繰り返し発生するLLMワークロードのコストと応答遅延の改善を目指します。
社内LLM・AIエージェント導入支援
社内資料やFAQを活用した社内LLMの導入をご支援します。

研究・開発RESEARCH AND DEVELOPMENT
AI推論最適化技術の研究開発
「省力化」と「安全性」
Cache AI紹介動画(英語音声・英語字幕)
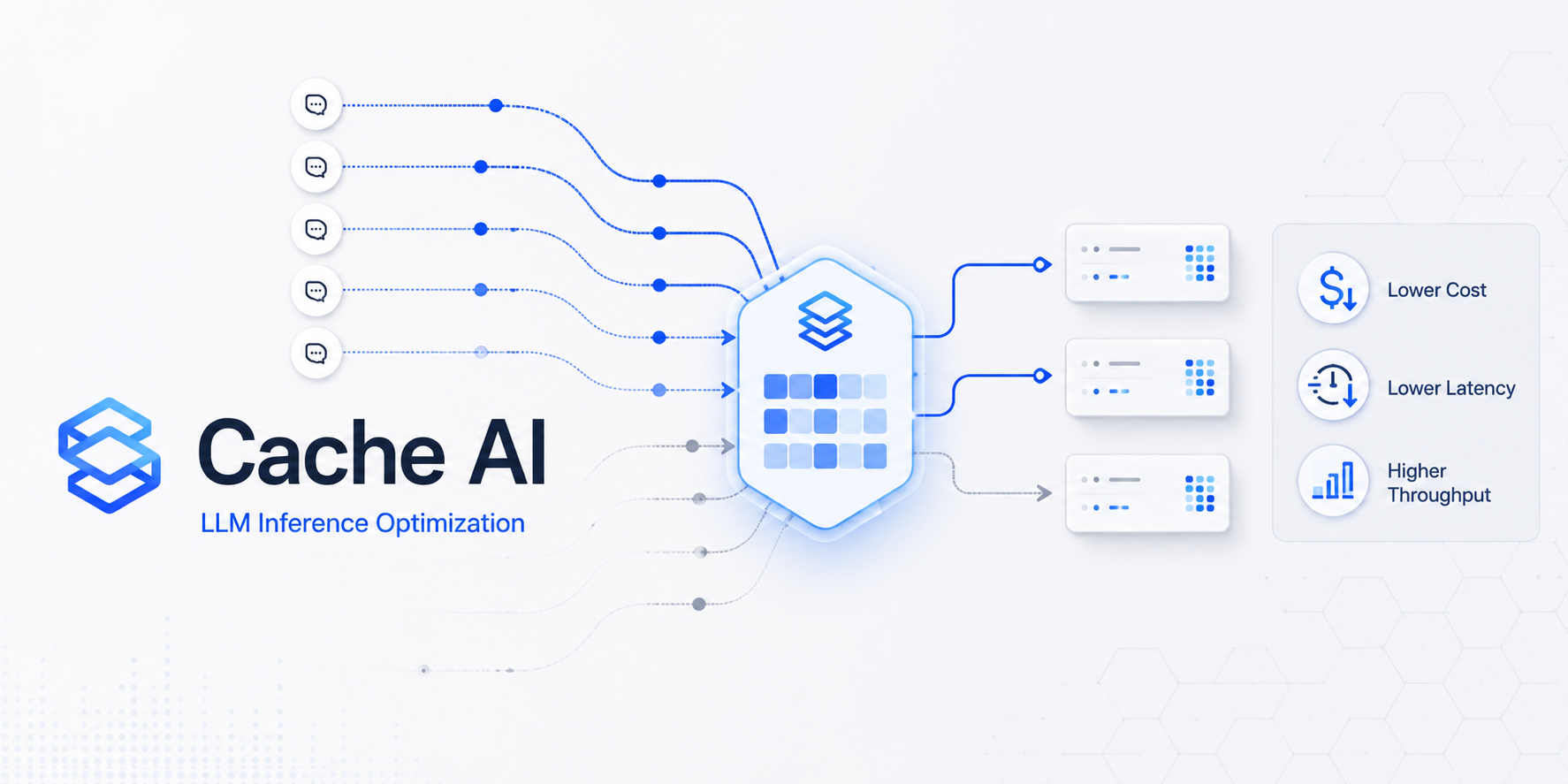
LLM推論最適化技術 Cache AI®
生成AIや大規模言語モデル(LLM)の業務利用が進む一方で、LLM推論には高い計算コスト、応答遅延、運用コストの増大という課題があります。
Cache AIは、繰り返し発生するLLMワークフローにおいて、重複する推論処理を削減し、コストと応答遅延の低減を目指すAIインフラ技術です。
Geek Guildは、AIモデルの効率化、推論最適化、運用コスト削減に関する研究開発を通じて、Cache AIの中核技術を開発してきました。Cache AIは、国内ではGeek Guildが展開し、海外市場では米国法人 CacheAI Technologies, Inc. を通じて商用展開、契約、パートナー対応を進めています。
 Cache AI
Cache AI
これまでの研究開発 SmallTrain
Geek Guildは、SmallTrainなどのAI基礎技術の研究開発を通じて、AIモデルの効率化、学習済みモデルの再利用、開発工数の削減に取り組んできました。
SmallTrainは、汎用的なディープラーニングフレームワークとして開発したオープンソースプロジェクトです。これらの研究開発知見は、現在のCache AIを中心としたAI推論最適化技術にもつながっています。
SmallTrainのオープンソース サイト
![]() SmallTrain
SmallTrain
人々の暮らしとまちを
最適化するAI提供実績BUSINESS RECORD

NEWS
VIEW MORE-
2026.04.15
米国大使館関連コンテンツでのGeek Guild米国展開紹介
米国大使館関連コンテンツで、Geek Guildの米国展開に向けた取り組みが紹介されました。
-
2026.03.15
広島AIプロセス フレンズグループ参加
Geek Guildは、G7広島サミットを契機に立ち上げられた広島AIプロセスのフレンズグループ・パートナーコミュニティに参加しました。
-
2026.03.05
SelectUSA Investment Summitの参加者代表として登壇
SelectUSA Investment Summit参加経験をもとに、米国展開に向けた準備と実践について共有しました。
-
2026.01.13
Japan Innovation Campusコワーキングメンバー採択
Geek Guildは、米国・シリコンバレーのスタートアップ支援拠点「Japan Innovation Campus」のコワーキングメンバーに採択されました。
-
2026.01.06
CES 2026 JETRO Japan Pavilion 出展
Geek Guildは、CES 2026のJETRO Japan Pavilionに出展し、Cache AIを紹介しました。